Framasoft invites you to try out the prototype of Lokas, a new speech-to-text transcription application that respects your privacy. This functional demo is also an experiment by Framasoft in the field of AI, accompanied by the Framamia website, which we present here (in French). 🎈Framasoft is 20 years old🎈 : Contribute to finance a 21st...
This is about a speech transcription program running on the company’s remote server. The app uploads your audio and the system sends you a transcript. You’ve got to be kidding. Reporting as spam.
The link takes you to their repos. The server repo has instructions on self-hosting directly on your server or with Docker. The app repo has code for both the iOS and Android apps. That’s good, because the iOS app at least doesn’t have a built-in way to select a different backend server.
Whisper is by OpenAI and as far as I know they have not shared the training code, much less the data sets, so the best you can do is fine-tune the models they’ve provided.
If use of Whisper is a problem, but the project is otherwise interesting to you, you could ask them to consider using a different STT solution (or allowing the user to choose between different options). I’m not aware of any fully open STT applications that are considered to be as capable as Whisper, but if you do, that would be great info to share with them.
Yes it’s nice that the phone app is free but STT is the difficult and important part. With Moonshine it might be possible to run the transcriber completely on the phone instead of having the STT on a remote server.
It’s interesting that they are able to do all that speaker distinguishing with just a single mic as found on both phones. There was a thread about phone features recently. Given this STT stuff, it could be useful to have a phone with 3 or 4 mics in the corners of the phone, like one of those tabletop conference mics, so it can figure out directionality of sound sources.


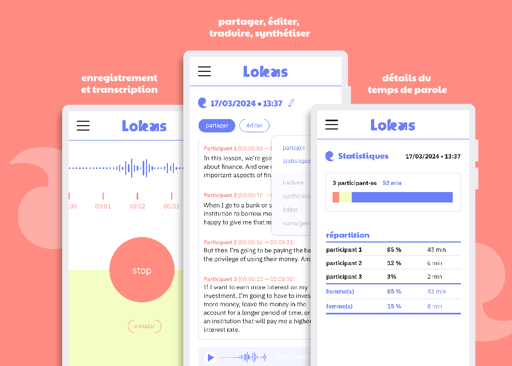
This is about a speech transcription program running on the company’s remote server. The app uploads your audio and the system sends you a transcript. You’ve got to be kidding. Reporting as spam.
It’s free software which you can host yourself. The source is here (GPLv3). You can read more about the people that make it here: https://en.wikipedia.org/wiki/Framasoft
It didn’t say that on the linked page. Is the AI model and training code and data also free?
Added: it looks like it uses Whisper for transcription. So the inference code is there but it’s unclear about the other stuff.
https://en.m.wikipedia.org/wiki/Whisper_(speech_recognition_system)
Anyway, thanks for the update.
Unless something has changed, it did. The page linked reads:
The link takes you to their repos. The server repo has instructions on self-hosting directly on your server or with Docker. The app repo has code for both the iOS and Android apps. That’s good, because the iOS app at least doesn’t have a built-in way to select a different backend server.
Whisper is by OpenAI and as far as I know they have not shared the training code, much less the data sets, so the best you can do is fine-tune the models they’ve provided.
If use of Whisper is a problem, but the project is otherwise interesting to you, you could ask them to consider using a different STT solution (or allowing the user to choose between different options). I’m not aware of any fully open STT applications that are considered to be as capable as Whisper, but if you do, that would be great info to share with them.
I get the impression that recreating the Whisper training code is possibly doable, but the data is a bigger task.
This is a possible Whisper alternative with maybe similar issues: https://petewarden.com/2024/10/21/introducing-moonshine-the-new-state-of-the-art-for-speech-to-text/
Yes it’s nice that the phone app is free but STT is the difficult and important part. With Moonshine it might be possible to run the transcriber completely on the phone instead of having the STT on a remote server.
It’s interesting that they are able to do all that speaker distinguishing with just a single mic as found on both phones. There was a thread about phone features recently. Given this STT stuff, it could be useful to have a phone with 3 or 4 mics in the corners of the phone, like one of those tabletop conference mics, so it can figure out directionality of sound sources.
They’re also involved in Fediverse development, they made Mobilizon as an event management platform
https://framablog.org/2022/11/08/mobilizon-v3-find-events-and-groups-throughout-the-fediverse/